概述
SQLAlchemy是一套使用python来处理数据的的工具包。
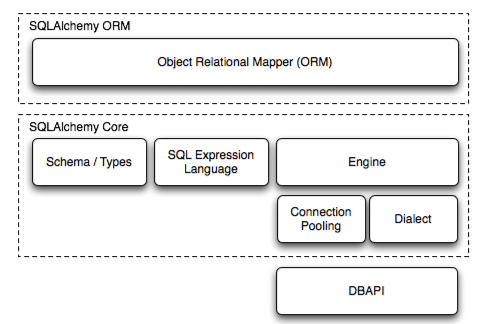
两个核心概念是ORM和Core。ORM是对象关系映射,是通过python操作数据的面向对象的工具。Core是使用SQL语句操作数据的工具。
对象关系映射(ORM)
引擎Engine
连接 (Connection)
SQL 表达式语言 (SQL Expression Language)
方言 (Dialect)
知识点
单表继承
想象你有一个水果店,卖各种水果:苹果、香蕉、橙子等。单表继承就像把所有水果的信息都记录在一张大表格上。这张表格有几列是所有水果共有的(比如“名称”、“价格”),还有一些列只适用于特定水果(比如苹果的“品种”,香蕉的“产地”)。
- 基类(Base Class):就像水果店的“水果”这个总称。它定义了所有水果的共同属性(列)。
- 子类(Subclass):就像具体的水果种类,比如“苹果”、“香蕉”。它们继承基类的属性,还可以有自己独特的属性。
- 鉴别器列(Discriminator Column):就像表格上的一列,用来区分不同种类的水果。比如,你可以有一列叫“类型”,它的值可以是“苹果”、“香蕉”等。
- 多态查询(Polymorphic Query):就像你问店员:“给我所有价格低于 5 元的水果”,店员会把符合条件的苹果、香蕉、橙子都拿给你,而不仅仅是某一种水果。
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy()
class Fruit(db.Model): # 基类
__tablename__ = 'fruits'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
price = db.Column(db.Float)
type = db.Column(db.String(50)) # 鉴别器列
__mapper_args__ = {
'polymorphic_identity': 'fruit', # 基类的标识
'polymorphic_on': type # 指定鉴别器列
}
class Apple(Fruit): # 子类
__mapper_args__ = {'polymorphic_identity': 'apple'}
variety = db.Column(db.String(50)) #品种
class Banana(Fruit): # 子类
__mapper_args__ = {'polymorphic_identity': 'banana'}
origin = db.Column(db.String(50)) # 产地
Flask-SQLAlchemy
| 知识点 | 描述 | 扩展 |
| db.Model | db.Model是所有模型的基类。
映射到数据库表,每一个基础db.Model的类都映射到数据库中的一个表。 关系映射:可以定义模型之间的一对多,多对多关系。 |
|
| db.Column | 用来定义数据库表 列 的类,定义了表的字段及属性,比如数据库类型、主键等。 | |
| db.relationship |
用来定义模型之间的关系,比如一对多、多对多关系。
|
backref 参数:用于创建反向引用,即在定义两个模型之间的关系时,让每个模型都可以通过对方轻松访问彼此。可以自定义名字。 |
| db.session | db.session 是 SQLAlchemy 提供的一个会话(session)对象,它用于执行数据库操作,如查询、插入、更新和删除。会话对象负责在数据库和程序之间管理对象,并处理事务。 | 查询数据:users = db.session.query(User).all()
添加新记录: new_user = User(username=’newuser’) 更新记录: user = db.session.query(User).filter_by(id=1).first() 删除记录: user = db.session.query(User).filter_by(id=1).first() |
在类中定义列信息
class Agents(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(191))
SQLAlchemy 需要重新定义一次列信息是因为它使用 ORM(对象关系映射)来映射数据库表到 Python 类。这种映射需要在类定义中明确列的信息,以便 SQLAlchemy 可以生成和操作数据库表结构。而 PyMySQL 是一个底层的数据库驱动,直接执行 SQL 语句,不需要 ORM 的这种映射过程
connection = pymysql.connect(host='localhost', user='user', password='passwd', database='db')
cursor = connection.cursor()
cursor.execute("SELECT id, username FROM users")
配置
flask_sqlalchemy.config
flask_sqlalchemy.config.SQLALCHEMY_DATABASE_URI: 告诉 Flask-SQLAlchemy 你用的是什么类型的数据库(SQLite、PostgreSQL、MySQL 等),以及数据库在哪里
SQLALCHEMY_ENGINE_OPTIONS: 字典, 告诉 Flask-SQLAlchemy 如何与数据库进行更精细的交互
SQLALCHEMY_BINDS: 如果你有多个数据库,这个配置可以让你为每个数据库设置不同的引擎选项
SQLALCHEMY_ECHO:
这个配置主要用于调试。如果启用它,Flask-SQLAlchemy 就会把你发送给数据库的指令(SQL 命令)打印出来,方便你查看。
SQLALCHEMY_RECORD_QUERIES:这个配置也是用于调试的。它会记录你的应用在一次请求中向数据库发送的所有查询,方便你分析。
SQLALCHEMY_TRACK_MODIFICATIONS:这个配置会监视你对数据库表所做的更改。
3.1 版中的更改:删除了 SQLALCHEMY_COMMIT_ON_TEARDOWN
默认驱动程序选项
为 SQLite 和 MySQL 引擎设置了一些默认选项,使其在 Web 应用中默认情况下更易于使用。 SQLite 相对文件路径是相对于 Flask 实例路径而不是当前工作目录。内存数据库使用静态池和 check_same_thread 在请求之间工作。
MySQL(和 MariaDB)服务器被配置为删除空闲 8 小时的连接,这可能会导致类似 2013: Lost connection to MySQL server during query 的错误。默认的 pool_recycle 值为 2 小时(7200 秒),用于在该超时之前重新创建连接。
引擎配置优先级
由于 Flask-SQLAlchemy 支持多个引擎,因此有关于哪个配置覆盖其他配置的规则。
大多数应用程序将只有一个数据库,只需要使用 SQLALCHEMY_DATABASE_URI 和 SQLALCHEMY_ENGINE_OPTIONS。
如果向 SQLAlchemy 提供了 engine_options 参数,它将为所有引擎设置默认选项。 SQLALCHEMY_ECHO 为所有引擎设置 echo 和 echo_pool 的默认值。 SQLALCHEMY_BINDS 中每个引擎的选项都会覆盖这些默认值。 SQLALCHEMY_ENGINE_OPTIONS 会覆盖 SQLALCHEMY_BINDS 中的 None 键,SQLALCHEMY_DATABASE_URI 会覆盖该引擎选项中的 url 键。
超时
某些数据库可能会配置为在一段时间后关闭不活动的连接。MySQL 和 MariaDB 默认情况下是这样配置的,但数据库服务也可能会配置这种类型的限制。这可能会导致类似 2013: Lost connection to MySQL server during query 的错误。 如果遇到此错误,请尝试将引擎选项中的 pool_recycle 设置为小于数据库超时值的值。 或者,如果您希望数据库经常关闭连接(例如,如果它在可能会重新启动的容器中运行),可以尝试设置 pool_pre_ping。 有关详细信息,请参阅 SQAlchemy 关于处理断开连接的文档。
模型和表
使用 db.Model 类定义模型,或使用 db.Table 类创建表。两者都处理 Flask-SQLAlchemy 的绑定键,以便与特定引擎关联。
- 用
db.Model类定义模型: 这是最常用的方式,更方便、更 Pythonic。Flask-SQLAlchemy 会根据你的模型自动创建对应的表。 - 用
db.Table类直接创建表: 这种方式更灵活,但需要你手动写 SQL。
初始化基类
想象一下,你正在设计一系列房屋。虽然每栋房子都有独特之处(比如卧室数量、颜色),但它们也有一些共同点(比如都有门窗、都需要地基)。在面向对象编程中,基类就像房子的通用蓝图,定义了所有房子都具备的基本特征。
SQLAlchemy 2.x 为你的模型提供了几个可能的基类:DeclarativeBase 或 DeclarativeBaseNoMeta。
DeclarativeBase: 这是最常用的基类,提供了声明式模型定义的全部功能。DeclarativeBaseNoMeta: 这是一个更轻量级的基类,不包含MetaData对象。如果你不需要自定义约束命名约定,可以选择这个基类。
你可以选择其中一个创建子类:
from sqlalchemy.orm import DeclarativeBase class Base(DeclarativeBase): pass
如果你希望启用 SQLAlchemy 对数据类的原生支持,可以添加 MappedAsDataclass 作为另一个父类。
from sqlalchemy.orm import DeclarativeBase, MappedAsDataclass class Base(DeclarativeBase, MappedAsDataclass): pass
自定义 MetaData 对象
你可以选择性地使用自定义的 MetaData 对象来构建 SQLAlchemy 对象。这允许你指定自定义的约束命名约定,使约束名称保持一致和可预测,这在使用 Alembic 进行数据库迁移时非常有用。
初始化扩展
定义好基类后,就可以使用 SQLAlchemy 构造函数创建 db 对象。
定义模型
要定义模型类,请继承 db.Model。与普通的 SQLAlchemy 不同,Flask-SQLAlchemy 的模型会在没有设置 __tablename__ 且定义了主键列的情况下自动生成表名。
from sqlalchemy.orm import Mapped, mapped_column class User(db.Model): id: Mapped[int] = mapped_column(primary_key=True) username: Mapped[str] = mapped_column(unique=True) email: Mapped[str]
定义数据表
要定义数据表,请创建 db.Table 的实例。与普通的 SQLAlchemy 不同,不需要提供 metadata 参数,Flask-SQLAlchemy 会根据 bind_key 参数选择合适的 metadata,或者使用默认的。
映射现有表 (Reflecting Tables)
如果你连接的数据库中已经存在表,SQLAlchemy 可以自动检测模式并创建具有相应列的表对象。这个过程称为映射(reflection)。你可以将这些表对象分配给模型类的 __table__ 属性,而不是自己定义完整的模型。
with app.app_context(): db.reflect() class Book(db.Model): __table__ = db.metadata.tables["book"]

