摘要
高级持续性威胁(Advanced Persistent Threats,APT)对现代网络安全构成严重威胁,促使研究和评估有效的检测技术。不断发展的APT威胁已激发了对防止其恶意活动的新策略的研究。本研究深入探讨了基于机器学习的APT检测技术。首先解释了APT及其特征以及攻击模型的具体信息。通过概述它们的攻击技术和策略,进一步分析了APT。本研究涵盖了APT攻击检测策略的广泛研究,重点关注机器学习技术。在APT检测的背景下,考虑了支持向量机(SVM)、k-最近邻算法(KNN)、深度置信网络(DBN)、决策树和卷积神经网络(CNN)。评估了每种方法在APT检测中的基本假设和适用性。本研究的主要目标是对上述机器学习方法的性能进行研究。为了实现这一目标,使用了Giuseppe Laurenza/I_F_Identifier数据集,该数据集包含各种网络流量场景。采用不同的性能指标,包括精确度、召回率、F1分数、准确度、真正例率和真负例率,来评估检测技术的有效性。本研究揭示的结果强调了卷积神经网络(CNN)在其他方法之上的优越性。精确度、召回率、F1分数、准确度、真正例率和真负例率等性能指标共同证明了CNN在准确和全面检测网络流量中的APT攻击方面的能力。这些发现不仅有助于持续讨论APT检测问题,还强调了CNN在加固网络安全系统以应对复杂威胁方面的有效性。
1.引言
如今,安全已经成为每个组织和机构的重要组成部分。几十年前,安全只是对军队和一些政府组织的主要关切。每个组织都有其安全威胁的监控、检测和缓解部门,负责处理对组织危险的未知威胁。然而,这些监控部门是不够的,因为他们每天都会收到新类型的恶意软件和新种类的攻击[1][2]。曾经有过这样的时候,入侵者或一群入侵者的目标是摧毁组织或诽谤竞争对手组织的财务损失。那些攻击是单次运行或短时间内的攻击。但在过去的几十年里,攻击者或攻击组织以缓慢而低调的方式进行攻击,以实现他们的目标。他们悄悄地渗透到目标组织中,窃取完整数据的使用权而不被发现。这些类型的攻击者或攻击组织被称为高级持续性威胁(APT)攻击。APT正如其名称所指,攻击者使用先进的技术、方法和工具,以持续很长时间来挖掘目标环境中的高度敏感的数据。APT入侵者保持低调,并逐渐增加他们在整个网络中的立足点,通过有系统的方法访问有用的信息,并将认证信息导出到他们的端点[1][3]。APT是一个迅速增长的网络安全威胁。APT由训练有素、经验丰富、财力雄厚、工具和资源支持的攻击者执行,他们的目标是获取组织的机密信息。他们攻击的持续时间取决于资助机构的意愿,或者直到他们被抓获[4]。
1.1 什么是APT?
APT(高级持续性威胁),又称为高级持续性攻击,是由训练有素和充分资金支持的攻击者执行的攻击。它不是由普通攻击者执行的。资助的机构的目标是获取其目标群体或机构的重要数据。APT与信息安全的名称有关,通常由国家或国家实施。APT的缩写由三个词组成[1]。
– 高级(Advanced):高级持续性威胁攻击者非常聪明,能够通过使用多阶段的攻击方法来改进技术和工具。
– 持续性(Persistent):APT攻击者非常坚持,以实现其目标并制定技术以避免被检测到。他们遵循低速度和低密度的攻击过程。
– 威胁(Threat):APT黑客专门针对特定组织来实现其目标。他们通常具有通过拒绝服务、数据曝露、破坏和/或更改数据来危害信息系统的能力。一般来说,黑客的目标是获取选定目标的访问权限,并从受损系统中窃取有关目标的信息。一旦他们进入目标组织,他们会长时间停留,收集对资助机构有用的信息。APT攻击者经常升级其技术,并涉及不止一个受损节点,而不仅仅是一个普通的攻击。根据美国国家标准与技术研究所(NIST)[2]的定义,APT攻击组织:“(i) 在较长时间内反复追求其目标。(ii) 适应防御者的抵抗努力。(iii) 决心保持执行其目标所需的互动水平。”Chen等人在[4]中总结了普通攻击和高级持续性攻击在各种特征方面的主要特点,如表I所示。
表一:普通持续攻击与高级持续攻击的对比差异
| 普通攻击 | 高级持续性攻击 |
|---|---|
| 攻击者 | 通常由一个人执行 |
| 目标 | 未定义,单一用户或单一系统 |
| 目的 | 经济特权,展示技能和才能 |
| 方法 | 一次性实施,适用于短时间 |
1.2 APT攻击模型:高级持续性威胁是如何工作的?
高级持续性攻击(APT)攻击,如上所述,经过精心策划和协调,以提高攻击成功的可能性,并分多个阶段执行攻击。为了了解APT是如何工作的,[5]中的作者阐述了不同的攻击树及其在执行系统安全方面的优势。这个攻击树提供了关于攻击可能发生的方式以及采用的安全措施来识别和防止系统受到这些攻击的信息。APT攻击通常按以下阶段传播:
1. 侦察(Reconnaissance):任何个人或一组APT攻击者都将从侦察开始。在这个阶段,他们对目标组织进行调查和分析。攻击者在这个阶段收集有关目标组织的资产、员工和连接的数据,以用于达到目标。他们了解调查的结构;他们对被攻击的系统了解得越多,攻击成功的可能性就越大。他们进行网络扫描,以识别网络上的开放服务、边界安全措施以及具有访问目标数据权限的网络用户。攻击者在侦察阶段收集有关员工的信息,如他们的兴趣、网站访问频率、使用的社交媒体平台,以及公司使用的信息和通信架构,如路由器、集线器、交换机、防火墙、网络地址、存储结构、安全平台、过时的系统、运行的机器、虚拟主机等。然后,攻击者使用社交网络中公开可用的信息,在那里他们可以开设账户,为每个目标员工创建个人资料[6]。
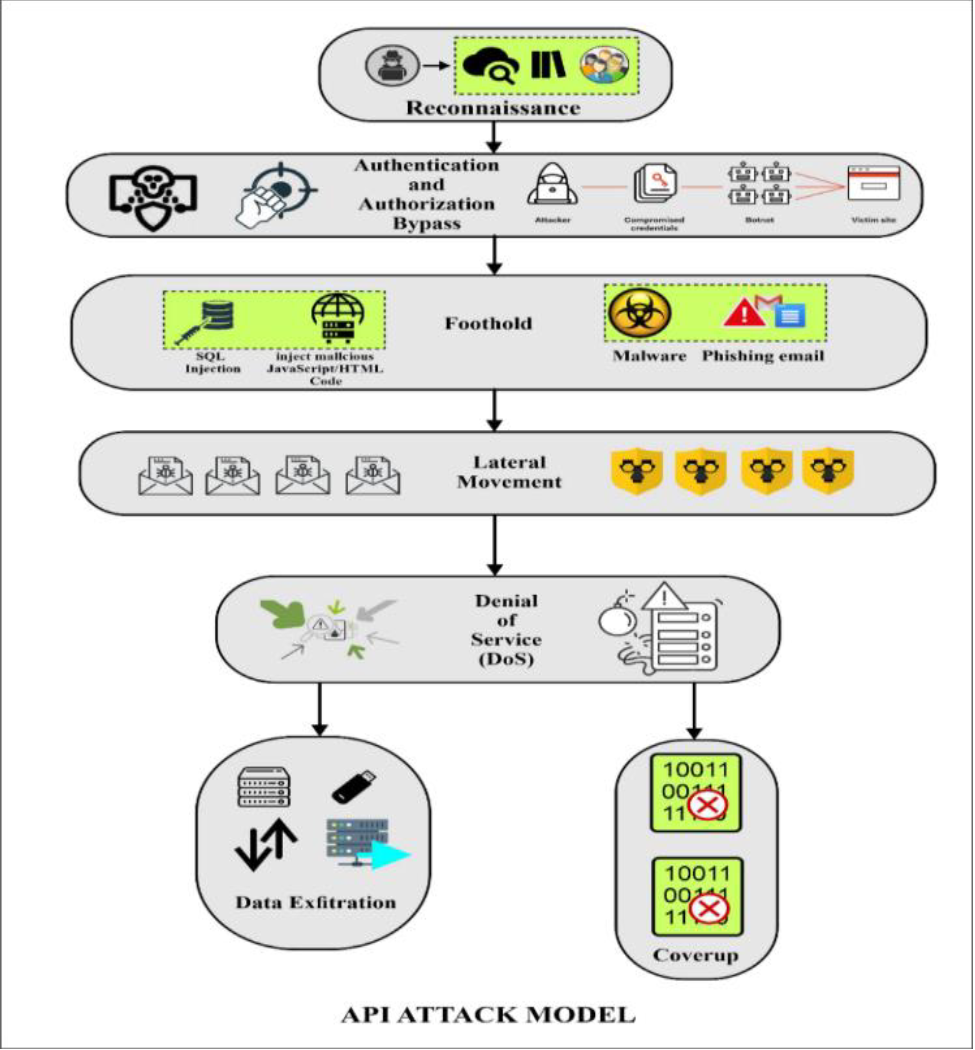
图1APT攻击模型
1) 攻击者希望通过这些信息变得更加持久,并深入了解系统。
2) 建立立足点 – 通过从侦察中收集信息,攻击者可以成功进入目标公司的计算机网络。APT攻击者使用终端用户计算机系统中的恶意软件功能来利用弱点。
I. 利用已知漏洞:常见漏洞和曝光清单(CVE)、开源漏洞数据库(OSVDB)[7]和NIST国家漏洞数据库(NVD)[8]是一些知名的漏洞数据库,其中包含了公开披露的漏洞,每个漏洞都可以通过特定的CVE-ID来识别。此外,在某些情况下,攻击者可以在深网和黑网的论坛上交流和收集有关已发现漏洞的有用信息。根据[3]中发布的报告,大多数APT攻击使用已知漏洞。因此,在发现漏洞后立即安装安全补丁非常重要。
II. 恶意软件:2016年,有3.57亿种不同的恶意软件变种,电子邮件感染率从2015年的每220封电子邮件下降到2016年的每131封电子邮件。根据赛门铁克的说法,分发垃圾邮件活动的僵尸网络是导致病毒感染率上升的原因。我们的APT攻击树显示了恶意软件如何通过钓鱼、闪存驱动器和Web访问传播。
III. 钓鱼攻击:赛门铁克的相同风险评估报告指出,攻击者更喜欢有针对性的钓鱼策略,尤其是那些采用商业电子邮件欺诈诈骗的策略,而不是传统的大规模钓鱼攻击。黑客使用常见的工程或类似的方法来收集有关目标群体的数据,然后发送包含恶意软件的电子邮件。这些欺诈性电子邮件被巧妙制作,以诱使收件人打开附件。对于不知道感染的员工来说,点击导致恶意软件安装和执行的附件或链接可能会危及组织的网络安全[9]。当执行此恶意软件时,它可能利用已知或未知的漏洞来访问组织的网络。
IV. 零日漏洞:零日漏洞是指制造商对计算机软件的问题要么不知道,要么知道但无法在攻击者能够利用之前修补的问题。APT黑客收集有关组织的计算机系统的信息,包括操作系统的版本、应用的更新和在这些系统上执行的应用程序,如防病毒和反恶意软件软件。下一步是查找这些版本中的任何安全漏洞,攻击者可以利用这些漏洞来进入目标的网络。然而,[3]的研究表明,大多数APT攻击都是通过已存在的漏洞执行的,只有很少一部分APT操作是通过零日漏洞执行的。在[10]中,李和刘集中研究了通过电子邮件传递的恶意软件执行的APT攻击。在查看了包含二进制文件的多封电子邮件之后,作者们开发了一种解决方案,涉及构建一个无向图,其中节点代表电子邮件地址,边代表将计算机链接起来的电子邮件
通信。他们希望这张图能为他们提供更多有关研究选定恶意软件的信息。这种方法的问题在于可能存在多个攻击节点,这些节点没有与其他攻击的联系,这可能表明攻击目标不够可见,或者可能存在不同的攻击,需要在确定是否存在APT攻击之前进行进一步研究[11]。
V. 网络下载:如前所述,钓鱼电子邮件可能包含需要解锁的恶意文件或导致员工在访问时无意中下载病毒的恶意网站链接。此外,攻击者可能利用目标员工访问的一个或多个网站上的漏洞,导致员工在访问该网站时无意中下载恶意软件。后一种攻击策略称为”饮水池”攻击。
3. 横向移动 – 在进入系统后,攻击者必须找到包含敏感信息或是组织基础设施的关键节点,这需要他们进一步深入网络。在此阶段,攻击者通过利用从上一级获得的优先用户的帐户信息来进行横向数据收集移动,试图在此阶段维持对目标信息的访问。如果组织的安全配置发生迅速更改,攻击者会使用先进的工具创建不必要的C&C通道。在获得对目标信息的访问权限后,目标信息的一份或多份不必要的副本将保存在充当”分段点”的服务器上。在此阶段,数据会进行分段、重组和编码,然后再被外传。攻击者试图访问目标网络上的其他主机,因为在此时,需要访问更高特权的权限以访问关键资源[1][3][6]。
4. 外传 – 此时,已经收集和打包在分段点服务器上的数据将通过加密通道发送到充当传送点的其他服务器。当攻击者的目标是获取组织的数据时,包括获取和将数据传送到攻击者的命令和控制中心的程序都属于这一阶段。在此阶段,攻击者管理着一个或多个远程服务器,用于传输被窃取的数据。如果攻击者想要重复地窃取数据,他们可以选择悄悄地逐渐泄露,也可以选择一次性完全泄露[6]。
5. 掩盖 – 仅当攻击者和资助攻击的组织或机构无法被定位、识别或追踪时,APT攻击才会成功完成,因此需要删除可能与他们联系的任何证据。在接下来的章节中,我们将更深入地讨论每个阶段以及各种攻击向量。在上述各个阶段中执行的APT攻击范例如图2所示。
1.3 APT攻击检测方法
为了在多个位置和各种网络层次上识别和阻止APT攻击的每个阶段,必须使用防御深度方法,其中包括足够的防御机制。通过将信息与这些各种保护方法相关联,任何机构或个人都可以免受APT攻击的威胁。监控方法主要依赖于这样一个概念,即即使入侵者可以通过使用其中一个正在使用的防御措施来防止被检测到,仍然存在另一层次的防御需要他们忽略。强大的防御与系统性方法必须确保没有一个保护阶段会被攻破。这种分层的防御方案还为攻击者提供了时间和风险估计,有助于他们采取缓解策略。监控方法、检测系统、欺骗技术和缓解程序是我们对APT保护技术进行分类的四个类别。由于每个类别都将进行详细审查,因此每个类别或子类别可以进一步细分为其他类别[6]。
1.监控方法
监控整个信息系统是抵抗APT的第一步,也是最基本的步骤。网络中不应该有未经监控的入口点,应该从多个方面和阶段对其进行检查。
I. 磁盘监控:必须监控组织网络的每个终端设备和元素,以查找任何恶意威胁,使用访问控制列表、防火墙和必要的防病毒程序。通过修补系统上运行的软件所需的漏洞,可以减少攻击者的入口点。此外,监视每个终端系统的CPU利用率将有助于识别终端系统级别的任何可疑活动[8]。
II. 内存监控:与从文件而不是从内存中进行处理相比,恶意软件可能会逃避检测的一种技巧。因此,这种攻击病毒会运行自身,以使用已在主内存中运行的程序。除非有一个单独的进程在后台运行,否则无法记录到任何东西,因为没有单独的进程在运行。
III. 数据包监控:与命令与控制中心的交互可能是APT攻击中最重要的元素。与命令与控制服务器的通信通常会发生多次,通常在系统被破坏后开始,然后在需要文件传输时继续。通过在组件级别之后查看任何具有新位置IP地址的数据包、包含大量数据的数据包以及传输到相同目标IP地址的大量数据包,可能会发现终端系统中的任何异常行为。
IV. 代码监控:编写无错误的软件程序通常是不可能的。即使在执行不同上下文时也很难保证代码是无错误的。威胁行为者使用此类错误作为入侵系统的一种方法。尽管在软件发布之前可能已经识别了其中一些错误,但在各种情况下执行代码时,仍然存在意外漏洞的可能性。如果在终端用户级别监视代码的性能并确保其在范围内执行而不使用意外的资源或占用通常不可访问的内存区域,可能会在威胁传播到其他计算机之前提前检测到潜在威胁[9]。
V.日志监控:日志不仅对法医调查至关重要,而且在有效使用时,它们还可以支持早期威胁检测甚至缓解。与仅仅拥有特定的日志记录不同,这些日志记录通常堆积在一起,以后再决定搜索入侵证据,这些日志文件的关系,包括内存利用日志、CPU利用日志、程序执行日志和事件日志等,可能提供大量的数据,有助于理解和支持网络或系统防御异常行为的尝试。
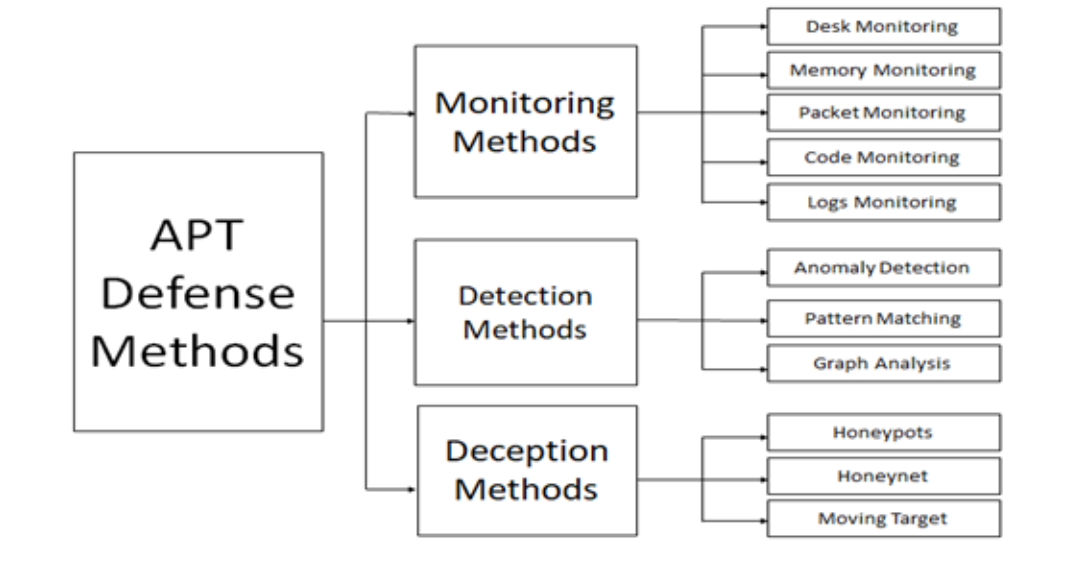
图2 APT防御方法
2. APT 防御方法
基于异常检测、基于模式匹配检测和基于图分析检测是 APT 检测方法可以划分的三个类别。
I. 异常检测:应对入侵者努力抵抗的能力构成了高级持续性威胁的关键属性之一。为了对抗这种威胁,所采用的预防策略必须从多个来源收集信息、从中学习,然后基于这些知识预测未来行动,以确定并应对潜在的未来行动。
II. 模式匹配:模式匹配是入侵检测和预防系统常用的一种方法。然而,这种方法本身也具有其优点。通过寻找进程或用户活动中的模式,可以确定不当行为。这是一种应用结构化入侵检测以查找 APT 的方法。某些模式匹配策略建立在网络流量时间序列数据中获取的高级结构化数据之上。模式匹配方法使用自然语言处理(NLP)来识别遥感和地理信息挑战中的活动。
III. 图分析:目前正在研究的领域之一是图分析,因为它可以增强对复杂组织的分析,并识别恶意活动。Johnson 等人提供了一种创新方法,利用图分析来评估网络的易受攻击性。他们的技术特别识别了威胁,威胁会使用移动哈希方法来进行横向移动和特权升级以实现攻击目标。一种简单的度量标准,用于在图上评估节点可能从其他随机位置访问的概率,可能会暴露网络的敏感性,可以用于检测威胁。
3. APT 欺骗方法
使用的复杂程度是进行攻击的一个重要特征。我们不能保证所有现有的防护因素都能保护我们免受恶意软件和新出现的系统漏洞的威胁。然而,最好的方式之一是做好充分准备,因此,欺骗的能力就显得尤为重要。在这种防御方法中,防御者通过构建陷阱,以虚假信息、网络或复制组织的生产环境的平台的形式,来困惑入侵者,但这些陷阱不是组织的实际关键资产的一部分。
I. 假蜜罐防御方法:欺骗的工具之一是假蜜罐。从 1990 年代开始,信息网络安全专家就开始使用它们,以困扰已经非法获取网络访问权限的网络犯罪分子,使他们与一个虚假系统进行互动。蜜罐可以以这种方式获取信息并分析黑客的行为。它们并不是用来检测威胁的。然而,自从蜜罐被发明以来,发生了很多变化,包括欺骗技术。人们发现蜜罐完全无法检测,因为它们的常规范围受到限制,而且被熟练的恶意行为分子轻易发现。今天的欺骗技术具有很大的潜力,尤其是用于快速准确的威胁检测。然而,要充分发挥这一潜力,欺骗必须远远超出蜜罐的范围,以充分实现这一潜力。
II. 蜜罐网络(一组蜜罐)防御机制:虚假系统或蜜罐的集合被称为蜜罐网络。它们维护在只有几台服务器上,每台服务器代表一个不同的环境,尽管看起来像是一个真实的网络。
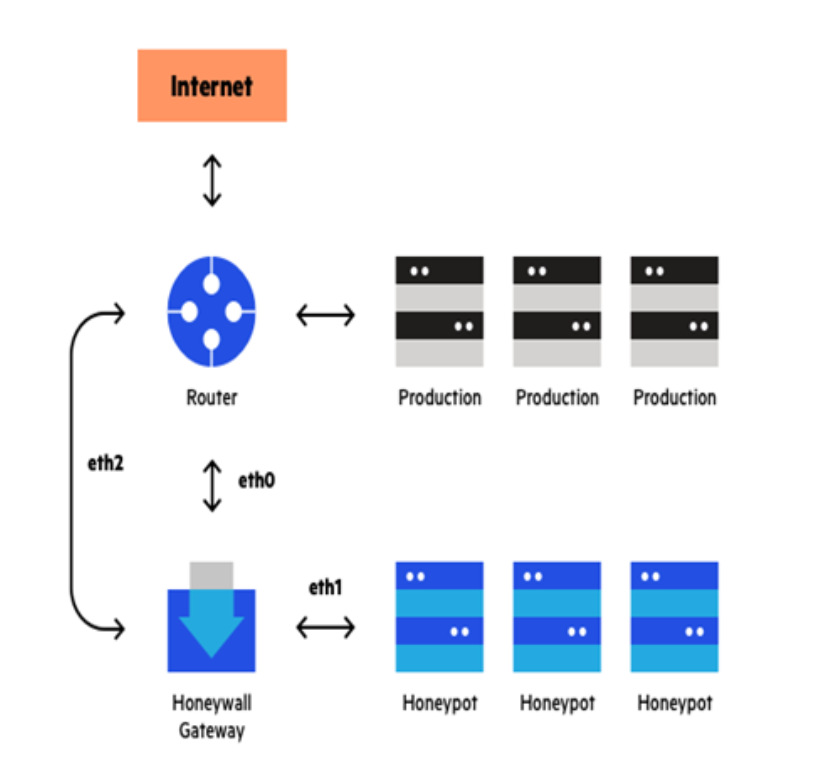
图 3. 蜜网(蜜罐网络)
并包含许多不同的系统。 “Honeywell” 监视进出设备的网络流量,并将其引导到蜜罐实施中。蜜罐可能会引入安全漏洞,以使黑客更容易陷入陷阱。攻击者可能会从蜜罐上的任何系统入侵。蜜罐收集入侵者的信息并将其传播到真实网络。蜜罐具有比基本蜜罐更自然感觉和更广泛覆盖范围的优势。由于它为攻击者提供了一个不同的内部网络,可能是真实网络的一个吸引人的替代选择,因此对于大型复杂网络而言,蜜罐是一个更可取的选择。
II. 移动目标防御:移动目标防御是一种极具前景的信息安全技术,用于对抗高级持续性威胁的缓解方法,它打破了未经授权的访问权限,以进行长时间的攻击。为了使攻击者更加复杂和困难,减少弱点的暴露和攻击机会,并增强系统的可靠性,移动目标防御[12]提供了设计、分析、测试和部署各种技术和策略的可能性。移动目标防御(MTD)是反复移动系统部件的行为。因此,攻击者更难(或更昂贵)有效攻击系统。可以根据安全建模和堆栈协议实施两种方式对 MTD 进行分类。对于安全建模的基础知识,MTD 分为混合、多样性和冗余。协议栈 MTD 描述为网络级别、主机级别和应用程序级别。
2.机器学习用于高级持续性威胁检测
可以使用异常检测、行为分析、预测分析、威胁情报和自动化等技术来应用机器学习。通过分析大量数据并从以前的趋势中学习,机器学习算法可以识别潜在的高级持续性威胁攻击,并帮助组织以快速和高效的方式应对这些攻击,从而使组织能够更好地保护其系统和数据免受复杂的网络威胁,并增强高级持续性威胁检测能力[5]。
2.1.用于高级持续性威胁检测的支持向量机(SVM)
在网络安全领域,支持向量机(SVMs)可以是一种有效的方法,用于识别高级持续性威胁(APTs)。APTs是一种特别设计用于绕过传统安全措施并长时间不被察觉的复杂网络攻击。
SVMs可以通过检测网络流量或其他数据源中的异常模式来帮助检测这些攻击。支持向量机模型的两个主要部分是决策边界和间隔。在高级持续性威胁检测的背景下,决策边界将数据分为两个分类,通常对应于合法和恶意行为。SVM算法在训练期间搜索间隔,也称为决策边界,它最大化了每个类的最近数据点之间的距离。这种分类方法被称为最大间隔分类,它基于这样一个观点,即间隔越大,模型过度拟合或错误分类传入数据的可能性越小。为了实现最大分类,SVM算法使用核函数将输入数据移动到具有更多维度的空间,从而更容易区分数据。SVMs通常使用线性、多项式、径向基函数(RBF)和S型等核函数。在训练后,基于新的未使用数据点相对于决策边界和间隔的位置,SVM模型可以用于预测先前未知的数据点的类别。如果数据点落在间隔内或在决策边界的错误一侧,它将被分类为恶意,并标记为潜在的高级持续性威胁。
以下是用于高级持续性威胁检测的SVM的数学模型:
给定一个带有标签的训练集,{(x1,y1),(x2,y2),…,(xn,yn)},其中xi是第i个数据点的特征向量,yi是相应的标签(1表示APTs,-1表示正常),SVM的目标是找到最大化分离两个类别的超平面。
超平面定义为:wT. xi+ b = 0——-(i)
其中w是大小为m x 1的权重向量,b是偏差项,xi是第i个数据点。
数据点xi与超平面之间的距离可以计算如下:d(xi) = |w. xi+ b| / ||w||—————–(ii)
其中,||w||是权重向量的欧几里德范数。
超平面与最近的数据点之间的距离被称为超平面的边距。最大化边距的超平面被称为完美超平面。以下句子可以用来定义SVM的优化问题:
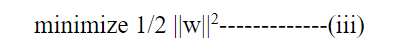
f(x) = sign(w*x + b)————-(v)
受到的约束条件为: yi(w. xi+ b) >= 1,其中 i = 1, 2, …, n—–(iv)
这个约束条件确保所有数据点都能够准确地被识别,并且具有至少一个边距,而||w||是权重向量的欧几里德范数。
可以使用二次规划来解决这个问题。在超平面被确定之后,可以通过确定新数据点落在理想超平面的哪一侧来对它们进行分类:f(x) = sign(w*x + b)————-(v)
其中sign是符号函数,根据参数的符号返回+1或-1。
在APT检测的背景下,从网络流量中提取的特征,如数据包长度、协议类型和其他特征,将作为输入向量x。基于这些特征,SVM将学习将流量分类为良性或恶意。可以应用以下规则来预测新数据点的类别:
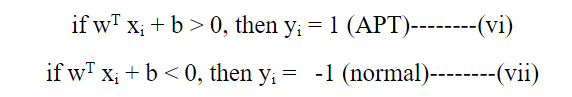
2.2 KNN用于高级持续性威胁检测(APT Detection)
在高级持续性威胁(APT)检测中,可以使用K-最近邻(KNN)机器学习技术。在APT检测中,已知威胁可能数量有限,KNN具有使用少量标记实例进行训练的能力,这是一个重要优势。通过手动更新系统以获取新获取的信息,KNN还可以快速修改以识别新的威胁。KNN可能在处理庞大数据库时计算成本较高,并且在处理高维或嘈杂数据方面可能不如其他算法(如SVM或深度学习)表现得好。
KNN用于高级持续性威胁(APT)检测的数学公式基于数据点之间的距离,如曼哈顿距离或欧氏距离。KNN通过测量数据点之间的距离来识别新威胁的K个最近邻居,并根据这些邻居的标签来估计其标签。
KNN模型可以如下表示:
给定一个包含n个数据点的数据集D,表示为(x1,y1),(x2,y2),…,(xn,yn),其中xi表示第i个数据点的属性,yi表示其标签。使用距离度量标准,如曼哈顿距离或欧氏距离,来确定D中每个数据点与x之间的距离。让x与每个数据点之间的距离分别为d1,d2,…,dn。根据它们的距离,选择x的K个最近邻居。令N为x的K个最近邻居的集合。确定N中每个标签的可能性。让pi表示N中具有标签i的数据点的总数。Pi/K是x符合标签i的机会。将x赋予具有最大可能性的标签。
使用欧氏距离来计算两个数据点x和y之间的距离的公式如下:
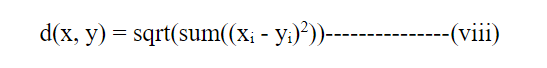
在公式中,xi和yi分别表示x和y的特征。以下方程可用于使用曼哈顿距离计算数据点x和y之间的距离:
d(x, y) = |x1 – y1| + |x2 – y2| + … + |xn – yn|
这个公式表示曼哈顿距离,它是通过将每个特征维度上的差的绝对值相加来计算两个数据点之间的距离。这种距离度量基于在每个维度上的坐标差的绝对值之和。
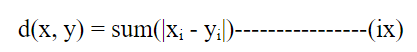
其中xi和yi分别是x和y的特征。
2.3 用于高级持续威胁检测的深度置信网络
深度置信网络(DBN)非常有用于检测高级持续性威胁(APT),因为它们可以发现庞大而复杂的数据集中的模式,无论数据是否嘈杂或不完整。网络的每一层隐藏单元都学会表示输入数据的更复杂的方面。网络总共由多个层组成。由于它使用了无监督学习技术进行训练,所以网络可以在没有标记示例的情况下识别数据中的模式。
以下是用于DBN的数学模型示例:设y为二进制输出变量,X为d维输入向量。可以使用L个二进制受限玻尔兹曼机(RBM)和一个最终的逻辑回归层来表示具有L个层的DBN。每一层k都有一个偏置向量bk,一个权重矩阵Wk和nk个二进制单元。带有权重Wk和偏置bk的RBM具有以下能量:
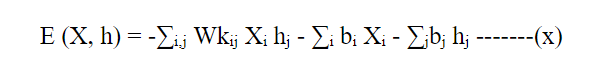
其中,Wkij是输入单元i和隐藏单元j之间的权重,Xi和hj分别是输入单元和隐藏单元的二进制状态。输入和隐藏单元之间的相互作用显示在能量函数的第一个项中,它们的偏置分别显示在第二个和第三个项中。以下是可见单元和隐藏单元的联合概率分布的定义:
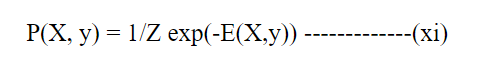
其中,Z是分区函数,用于确保分布的归一化。然后,使用隐藏层的激活来计算输出层的概率,并且由以下公式给出:
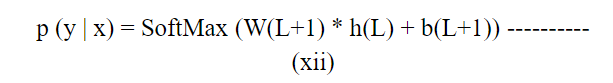
其中,SoftMax是一个归一化函数,确保概率相加等于1,p(y | x)是在给定输入x的情况下输出y的概率。无监督的预训练是训练DBN的一种方法,它涉及使用受限玻尔兹曼机(RBM)分别学习每一层的权重和偏差。在完成预训练后,可以使用反向传播等监督学习策略来改进DBN。 DBN的训练包括两个阶段,即贪婪的逐层预训练阶段,其中每一层被训练为一个RBM,以及微调阶段,在该阶段整个网络使用反向传播进行调整。在预训练期间,学习每一层的权重和偏差,以增加训练数据的可能性。在微调期间,网络被训练以最小化成本函数,如交叉熵损失。在训练后,DBN可以用于各种任务,包括分类、回归和聚类。在经过训练后,DBN可以用于检测传入网络流量中的异常,以增强持续性威胁检测,从而可以通过学习一组典型的正常网络流量特征,将明显偏离这些特征的任何传入通信标记为可能是恶意的。
2.4. 用于高级威胁检测的决策树
决策树用于高级持续性威胁检测决策树是一种可以用于检测高级持续性威胁(APTs)的机器学习技术。该算法基于已知的APTs和非APTs的标记数据集进行训练,以便在APT识别中使用决策树。然后,根据训练数据集中APTs和非APTs的特征和特征,决策树会制定一组规则。在测试阶段,当将样本提供给决策树时,该算法将使用这些规则来确定新样本是否为APT。为了得出这个结论,决策树考虑了样本的许多特征,包括其网络流量模式、系统日志文件和行为模式。决策树特别有助于APT检测,因为它们可以处理大量数据,并且可以发现数据中的模式,这可能对人类来说很难注意到。决策树对于持续性威胁的检测和预防是一个有用的工具,因为它们可以随着时间的推移进行更改,以便发现新的APTs。用于构建用于APT检测的决策树的一个可能的数学方程式是:
IF [Feature 1] <= [Threshold 1] AND [Feature 2] <= [Threshold 2] AND … AND [Feature n] <= [Threshold n] THEN [Classify as APT]ELSE [Classify as Not APT]
在这个方程中,[Feature 1]、[Feature 2]、…、[Feature n]代表我们用来识别APT的关键特征或条件。每个特征都与一个阈值值([Threshold 1]、[Threshold 2]、…、[Threshold n])相关联,该阈值值确定特征是否存在或不存在。
2.5.卷积神经网络(CNN)
卷积神经网络(CNN)是一种深度学习技术,可应用于网络安全以检测高级持续性威胁(APTs)。尽管CNN主要用于图像处理任务,但它们也可以用于其他类型的数据,例如网络流量序列或系统调用模式。CNN算法的不同层次包括卷积层、池化层和全连接层。池化层用于降低特征图的大小,而卷积层负责识别输入数据中的特征。使用全连接层来使用已学习的特征对输入数据进行分类。
在APT检测的背景下,CNN算法可以在包含良性和恶意数据的数据集上进行训练,数据集的特征作为CNN的输入。通过将输入数据经过卷积和池化层的处理,CNN学会识别表明良性和有害材料的模式和特征。然后,全连接层将数据分类为良性或有害。对于APT检测,CNN算法具有许多优点。它能够处理高维数据,并且擅长查找对APT检测重要的特征。此外,由于已知的APT不多,CNN可以在大规模数据集上进行训练,这在APT检测的背景下特别有帮助。
一个用于高级持续性威胁(APT)检测的CNN的数学模型可能包括以下组成部分:
1. 输入层:该层接收输入数据,可以是网络流量或系统日志。数据通常以矩阵或张量的形式表示。
2. 卷积层:该层使用滤波器从输入数据中提取特征。通常使用的滤波器是移动经过输入数据的小矩阵,逐个相乘和相加元素。
3. 激活层:卷积层的输出在此层应用非线性激活函数。激活函数用于为模型提供非线性特性,使网络能够学习更复杂的特征。
4. 池化层:通过降低激活层输出的维度,池化层降低了模型的计算成本,增强了对噪声和输入数据变化的抵抗力。
5. 全连接层:该层将一组输出类别转化为前一层的输出。通常,在全连接层之后使用SoftMax激活函数,将输出分数规范化为输出类别的概率分布。
6. 输出层:输出层中将存在与APT类别数量相同的神经元,该层使用交叉熵损失函数来确定预期的APT类别标签与实际输出之间的误差。
7. 损失函数:此函数用于计算模型预期输出与实际输出之间的差异。在训练期间,模型的目标是减少此损失函数。
8. 训练:为了最小化损失函数,模型将使用反向传播和梯度下降进行训练。在训练期间,将馈送带有标签的数据批次通过网络,并改变模型的权重和偏差以减少损失。
9. 评估:训练好的模型将在单独的测试集上进行评估,以测量其性能。可用的性能指标包括准确度、精确度、召回率和F1分数等。
10. 优化算法:此方法用于在训练期间更新模型的参数以减少损失函数。随机梯度下降算法及其变种是众所周知的优化算法。
通过组合这些元素,模型可以分析网络流量数据并找到可能指向存在APT的趋势。然而,应理解模型的效力将取决于训练数据的质量和多样性,以及具体针对的APT威胁。卷积神经网络(CNNs)是深度学习算法的一个子集,已被应用于网络安全中的高级持续性威胁(APTs)的识别。APTs是一种专门用于获取敏感数据且长时间不被察觉的网络攻击。CNN的数学方程可以分解为以下步骤:
卷积操作:一组可学习的滤波器(也称为卷积核)与输入图像卷积,以创建一组特征图。卷积操作的数学表示为:
数学方程中的一般CNN可以写为:
其中,W是一组可学习的权重(也称为卷积核或滤波器),y是CNN的输出,f是激活函数(如ReLU或sigmoid),f是应用于输入数据的激活函数。卷积操作的输入数据可以是单个图像或一系列图像,它涉及在输入数据上滑动卷积核并计算卷积核与输入的局部区域之间的点积。如果输入数据是网络流量数据,x可以代表数据包或流量。
卷积运算:
在上面的公式中,F(i,j)代表卷积操作在特征图中位置(i,j)的输出,I(i+x-1, j+y-1)代表输入图像中位置(i+x-1, j+y-1)的像素值,w(x,y)代表滤波器中位置(x,y)的权重(或卷积核系数)。
激活函数:
激活函数逐元素地应用于卷积操作的输出,引入了模型的非线性性。最常用的激活函数是修正线性单元(ReLU),可以用数学表示为:
ReLU激活函数 f(x) = max (0, x) ——–(xv)
其中,f(x)代表输入x的激活函数的输出。
池化操作:
使用池化操作对特征图进行下采样,以降低数据的空间维度,使模型更具计算效率。最常用的池化操作是最大池化操作,它选择滑动窗口内的最大值。最大池化操作可以用数学表示为:
P(i, j) = max(I(i+x-1, j+y-1)) ——–(xvi)
其中,P(i, j)代表下采样特征图中位置(i, j)的最大池化操作的输出。位置(i, j)对应于最大池化操作当前考虑的矩形区域的左上角。矩形区域的大小由最大池化滤波器的大小确定。例如,如果最大池化滤波器的大小为(x, y),那么在位置(i, j)处,最大池化操作考虑的矩形区域是由索引(i+x-1, j+y-1),(i+x-1, j),(i, j+y-1)和(i, j)定义的输入特征图的子矩阵。输出值P(i, j)只是这个矩形区域内的最大值。
P(i, j)由以下公式给出:
P(i, j) = max{F(i+x-1, j+y-1), F(i+x-1, j), F(i, j+y-1), F(i,j)}——(xvi)
其中,F(i, j)代表输入特征图在位置(i, j)的值。这个公式表示P(i, j)等于考虑的矩形区域内的四个位置上的值的最大值。
3. 效果分析
这项研究的目的是检验各种机器学习技术在检测高级持续威胁(APT)时的性能。在这项研究中,我们使用了支持向量机学习、深度信念网络、K最近邻、决策树和卷积神经网络进行分析。用于性能评估的数据集是Giuseppe Laurenza/I_F_Identifier数据集[27]。它已被用来评估各种机器学习算法和技术在检测和分类网络攻击方面的性能。所有标准的数据挖掘过程,如数据清理、预处理、归一化、可视化和分类,都在Python中实施。训练数据集被归一化为0到1之间。
4.结果与讨论
4.1.准确性
各种机器学习算法的准确性评分如图4所示,它提供了有关它们在分类挑战中表现如何的有用信息。卷积神经网络(CNN)以0.894的最高准确性领先,并展示了其卓越的预测能力。人工神经网络(ANN)以0.887的准确性位居第二,证明了其可靠性。支持向量机(SVM)和K最近邻(KNN)的准确性分别为0.875和0.883,两者都表现出色,突显了它们在分类中的实用性。决策树(DT)方法以0.874的准确性紧随其后。另一方面,贝叶斯学习(BL)以0.868的准确性稍显落后,并有改进的空间。总之,CNN和ANN在准确性方面表现出色,其次是SVM、KNN和DT,而BL在精确分类方面有改进的空间。
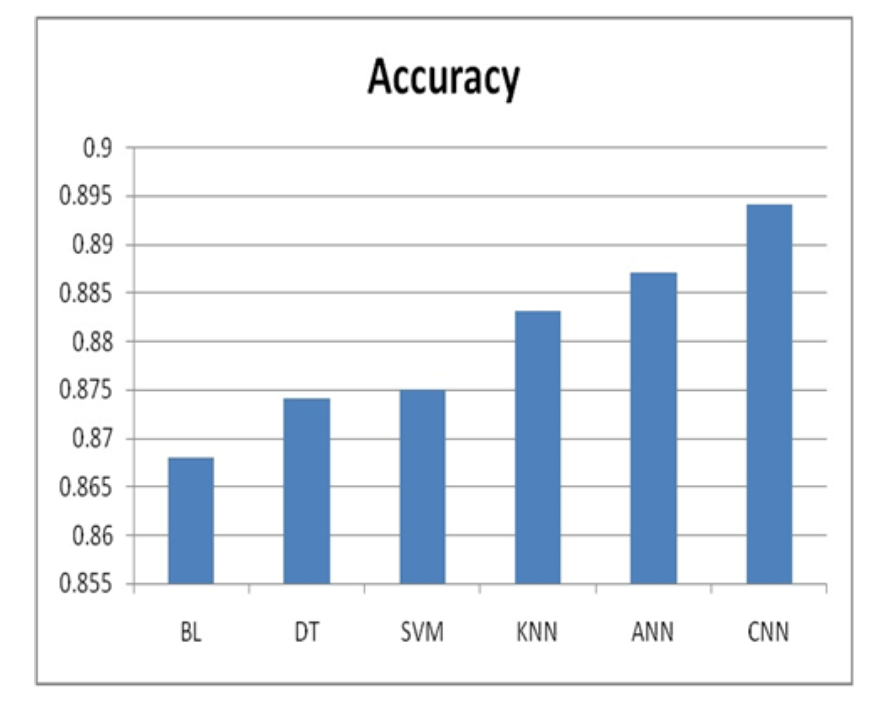
图4 各种ML算法的准确率
4.2.真正例率
图5中的真正例率(TRP)排名显示了机器学习系统识别正例的能力。在这种情况下,每个算法显示的TRP分数不同。人工神经网络(ANN)具有0.84的TRP,紧随卷积神经网络(CNN)之后,后者的TRP最高,为0.843。支持向量机(SVM)、决策树(DT)和K最近邻(KNN)的TRP分别为0.825、0.818和0.838,同样表现出色。通过CNN和ANN在这一领域表现出色,这些结果显示了所有算法在识别正事件方面的高效性。
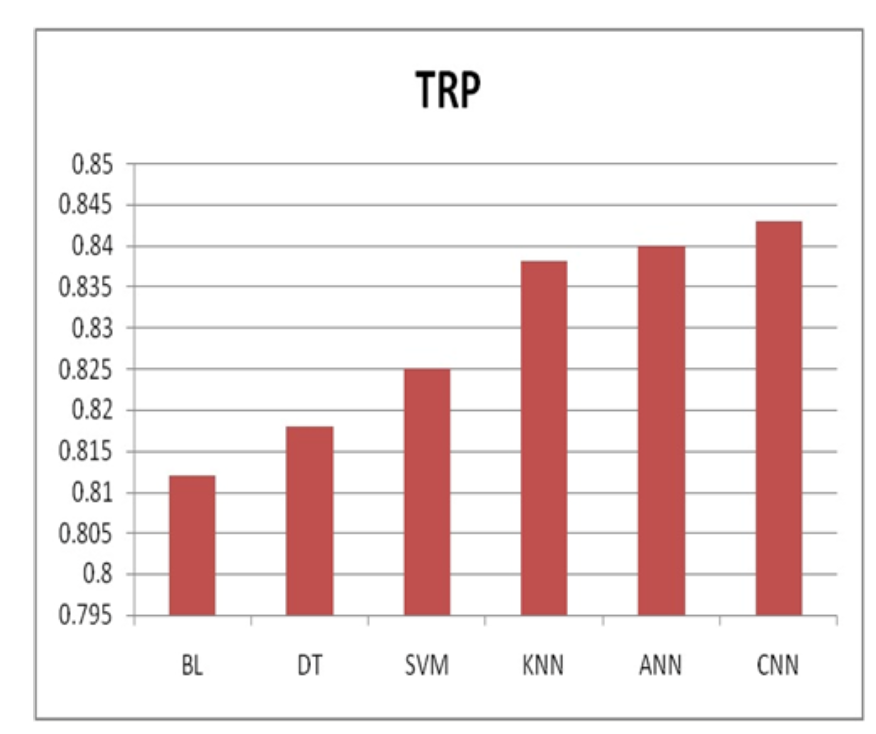
图5 各种ML算法的真阳性率
4.3.真负例率
在图6中,真负例率(TNR)分数显示了机器学习系统准确检测负例情况的能力。在这种情况下,所有算法呈现出不同的TNR分数。人工神经网络(ANN)紧随卷积神经网络(CNN)之后,后者的TNR最高,为0.866。K最近邻(KNN)、决策树(DT)和支持向量机(SVM)表现出色,分别具有0.848、0.844和0.861的TNR分数。这些结果表明,所有算法在识别负面事件方面都具有很高的潜力,CNN和ANN在这一领域表现出色。
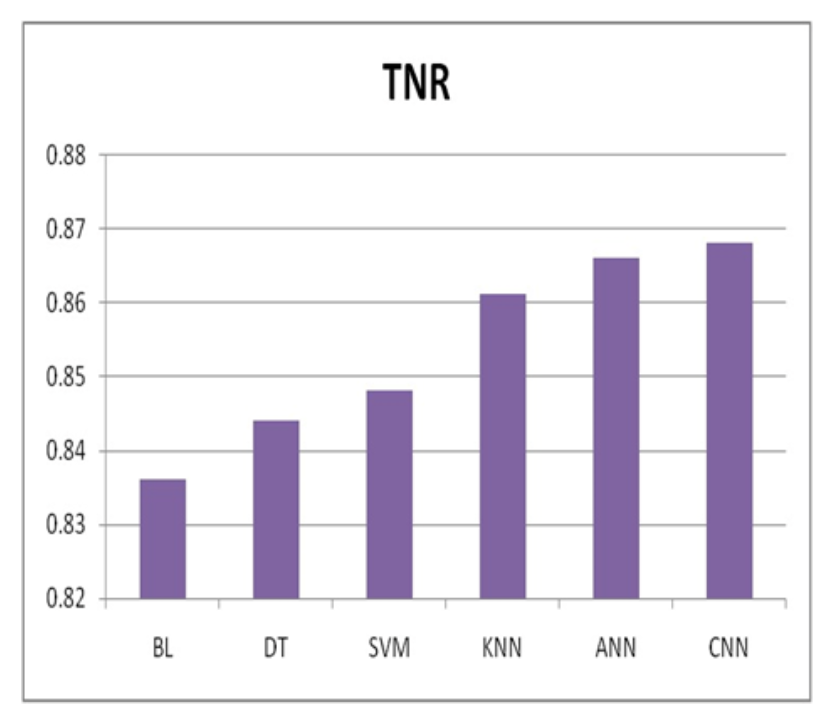
图6 各种ML算法的真阴性率
4.4.假正例率
在图7中,假正例率(FPR)评分展示了机器学习算法在分类任务中防止假阳性错误的效果。在这种情况下,所有算法都展示出不同的FPR评分。卷积神经网络(CNN)以最低的FPR 0.132脱颖而出,突显了它降低假阳性分类的能力。其次是人工神经网络(ANN),其FPR为0.134,凸显了其在处理假阳性方面的可靠性。支持向量机(SVM)、决策树(DT)和K最近邻(KNN)的FPR分数分别为0.152、0.156和0.139,表现同样出色,表明它们降低假阳性错误的能力。这些结果表明,所有算法在降低假阳性方面都表现出色,其中CNN和ANN在这方面表现突出。
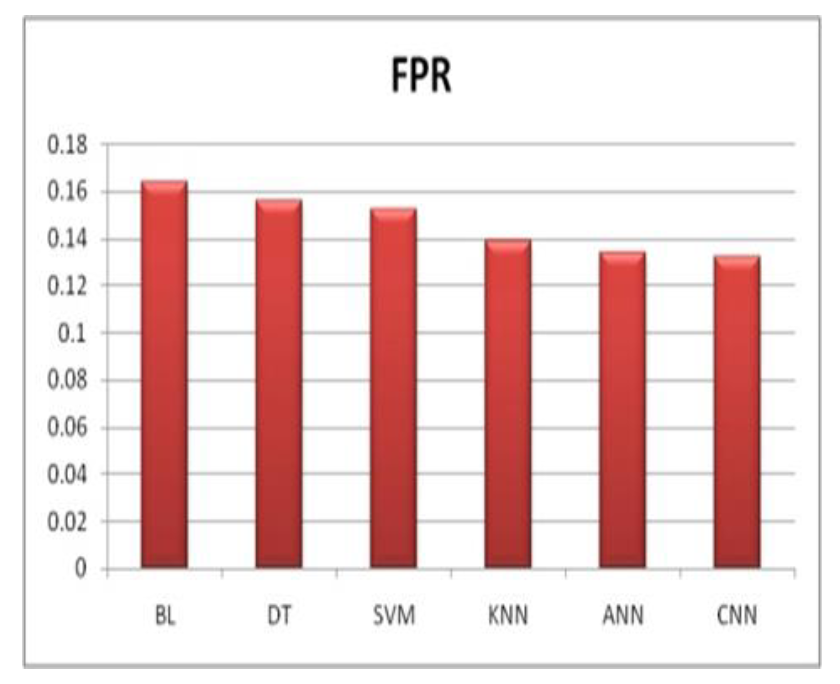
图7各种ML算法的假正例率
4.5.假负例率
在图8中,假负例率(FNR)评分提供了关于算法在分类测试中检测正例的能力的信息。在这种情况下,所有方法的FNR评分不同。卷积神经网络(CNN)以最低的FNR 0.157脱颖而出,突显了其在识别正例方面的准确性。其次是人工神经网络(ANN),其FNR为0.16,紧随其后,强调了其在这一领域的可靠性。支持向量机(SVM)、决策树(DT)和K最近邻(KNN)的FNR分数分别为0.175、0.182和0.166,同样在识别正面情况方面表现出色。在这一领域,CNN和ANN表现出色,这些结果显示了所有算法在识别正面事件方面的效果。
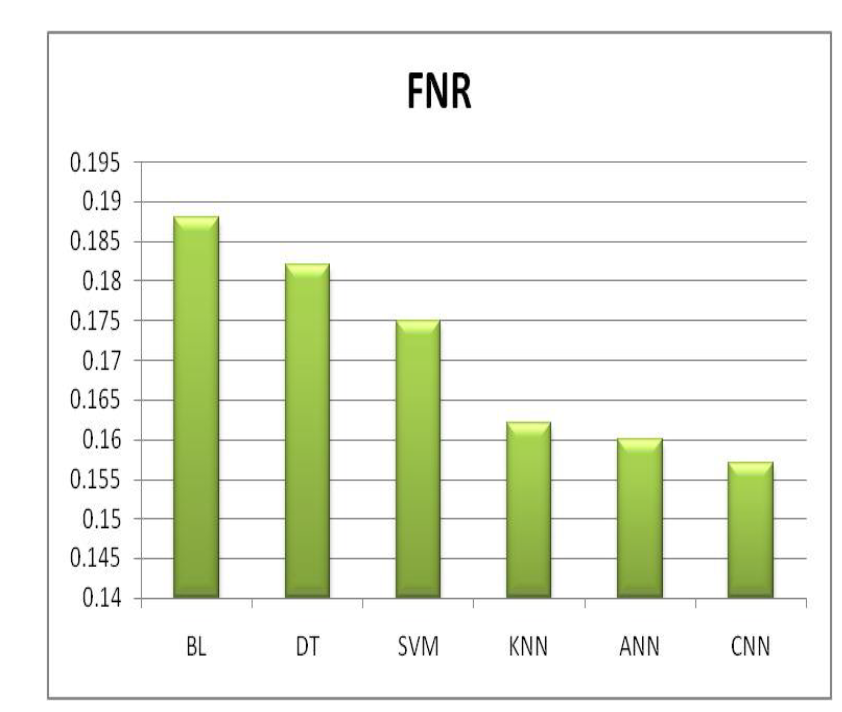
图8 各种ML算法的漏报率
4.6.召回率
在图9中,召回率分数显示了算法在分类挑战中准确识别正例的能力。各种算法的召回率评分各不相同。卷积神经网络(CNN)以0.843的召回率领先,并展示了其出色的识别正面情况的能力。其次是人工神经网络(ANN),其召回率为0.84,以其可靠性脱颖而出。支持向量机(SVM)、决策树(DT)和K最近邻(KNN)的召回率分别为0.825、0.818和0.838,同样表现出色,突显了它们在检测有利情况方面的能力。这些结果表明,所有算法都成功地识别了正面示例,其中CNN和ANN在这方面表现出色。
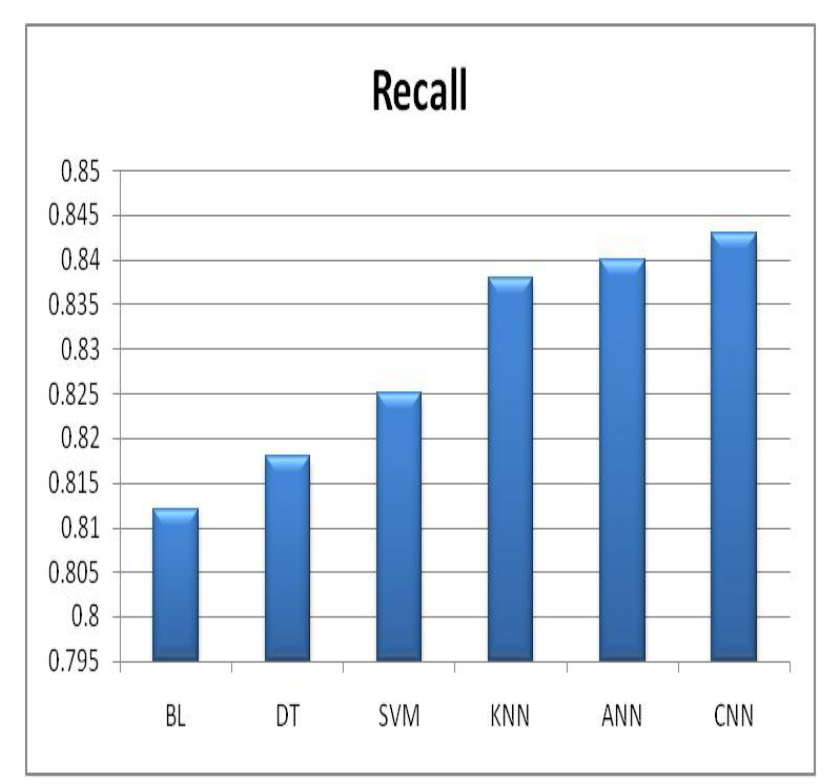
图 9 各种 ML 算法的回顾
4.7.精确度
精确度分数显示了算法在分类测试中进行精确的正面预测的能力,如图10所示。在这种情况下,所有算法都展现出不同的精确度评分。卷积神经网络(CNN)以0.864的精确度分数领先,并展示了其生成准确的正类别分类的能力。其次是人工神经网络(ANN),其精确度为0.862,强调了其可靠性。支持向量机(SVM)、决策树(DT)和K最近邻(KNN)的精确度分别为0.844、0.839和0.857,同样表现出色,突显了它们在生成准确的正面预测方面的能力。这些发现表明,所有算法都能够进行准确的正类别预测,CNN和ANN在这方面表现出色。
4.8.F-1分数
F1分数显示了机器学习系统中精确度和召回率的平衡情况,如图11所示。在这个分析中,卷积神经网络(CNN)和人工神经网络(ANN)分别具有约0.853和0.851的F1分数,展示了它们在平衡准确的正面预测和正确识别正例方面的能力。支持向量机(SVM)、K最近邻(KNN)和决策树(DT)的F1分数分别为约0.835、0.847和0.828,同样表现出色,突显了它们在实现这种平衡方面的能力。贝叶斯学习(BL)的F1分数约为0.822,表现出色。这些发现展示了这些算法在各种有趣但实际的方式中如何平衡精确度和召回率。
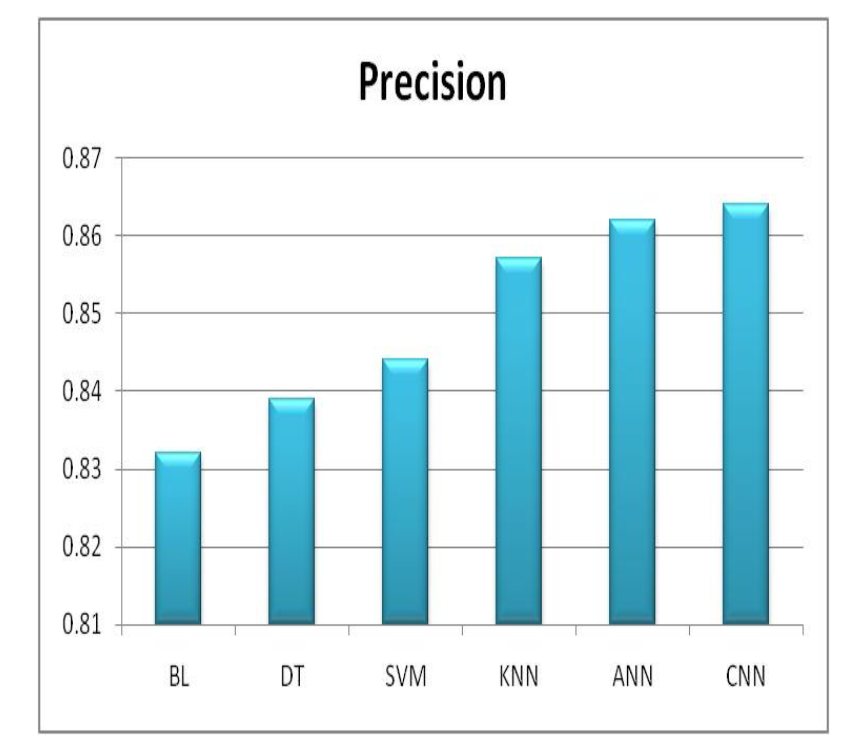
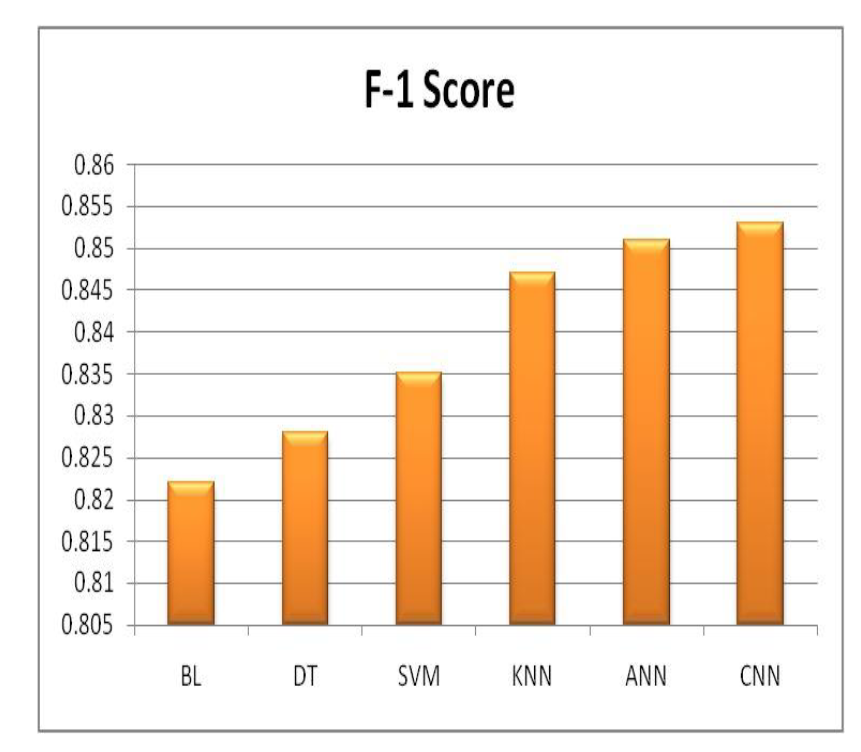
Fig 10 各种ML算法的精确度 图11F-1 各种ML算法的得分
5.结论
在与高级持续威胁(APT)不懈的斗争中,开发和评估有效的检测技术至关重要。本文对APT检测方法进行了全面分析,重点关注机器学习方法。通过深入探讨APT、它们的攻击模型以及各种检测方法,本研究揭示了这些持续且复杂的网络威胁所带来的复杂性和挑战。对于APT检测的机器学习技术,包括支持向量机(SVM)、k-最近邻(KNN)、深度信念网络(DBN)、决策树和卷积神经网络(CNN)的评估,为我们提供了有关它们在网络安全领域的有效性的宝贵见解。在NSL-KDD数据集上进行的评估涵盖了多种网络流量场景,使我们能够在关键性能指标如精确度、召回率、F1分数、准确度、真正例率和真负例率上进行了有力的比较。结果明确表明,在所研究的技术中,卷积神经网络(CNN)在APT检测方面表现出色。CNN表现出卓越的性能,在所有评估的指标上都达到了较高的值。这一发现强调了CNN作为巩固网络安全系统抵御APT威胁的强大工具的潜力。尽管这项研究取得了令人信服的成果,但必须承认网络安全形势是不断变化的。随着APT的演变和适应,持续的研究和创新对于应对这些威胁至关重要。未来的工作可以探讨多种检测方法的整合或引入实时数据流以提高APT检测系统的准确性和稳健性。
总之,这项研究强调了机器学习的重要性,特别是卷积神经网络的有效性,以降低高级持续威胁(APT)带来的风险。通过加深对这些检测技术的理解,我们为更具弹性和适应性的网络安全措施铺平了道路,提供了更强大的防御,以抵御不断演变的网络威胁世界。
6. 附件
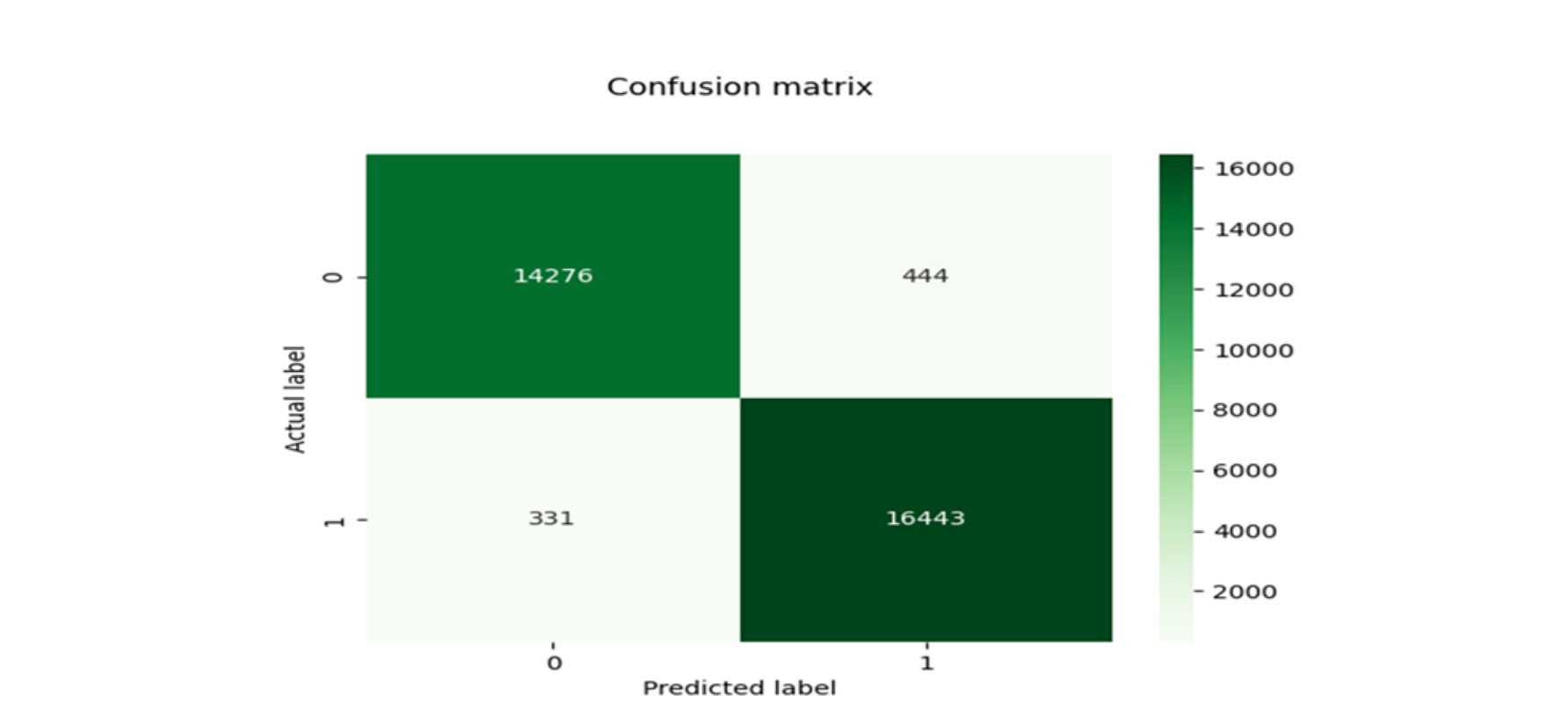
混淆矩阵支持向量机

混淆矩阵 K 最近邻混
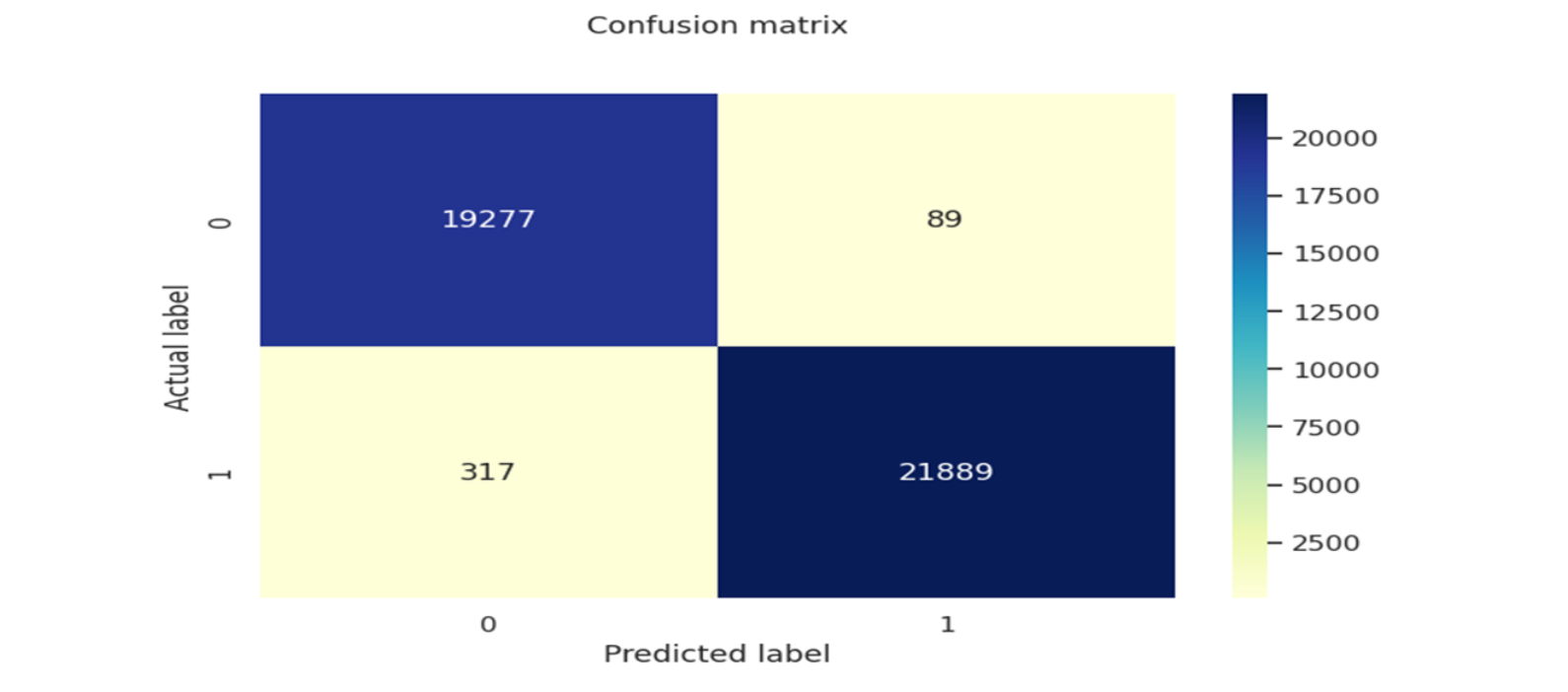
淆矩阵人工神经网络
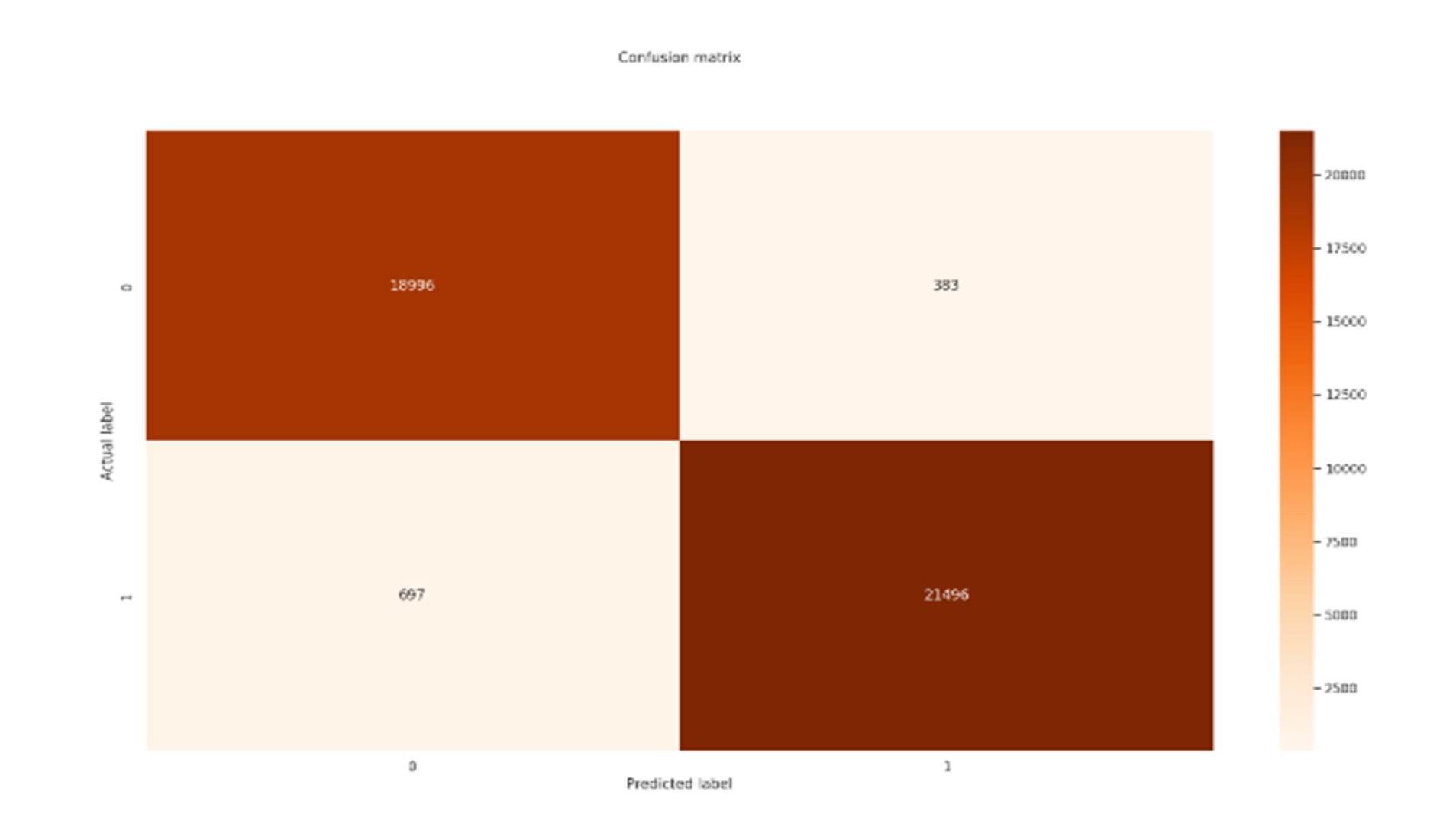
混淆矩阵决策树

绩效评估矩阵
参考文献
以下是您提供的所有26个参考文献:
1. Asharani, A., Myneni, S., Chowdhary, A., & Huang, D. (2019). A Survey on Advanced Persistent Threats: Techniques, Solutions, Challenges, and Research Opportunities. IEEE Communications Surveys & Tutorials, 21(2), 1851-1877.
2. Chu, W. L., Lin, C. J., & Chang, K. N. (2019). Detection and Classification of Advanced Persistent Threats and Attacks Using the Support Vector Machine. Applied Sciences, 9(21).
3. Xie, Y. X., Ji, L. X., Li, L. S., Guo, Z., & Baker, T. (2020). An adaptive defense mechanism to prevent advanced persistent threats. Connection Science, 33(2), 359-379.
4. Li, Z., Cheng, X., Sun, L., Zhang, J., & Chen, B. (2021). A Hierarchical Approach for Advanced Persistent Threat Detection with Attention-Based Graph Neural Networks. Security and Communication Networks.
5. Do Xuan, N., Cho, H. D., Dao, M. H., Nguyen, T., & Hoa Dinh, T. (2020). APT Attack Detection Based on Flow Network Analysis Techniques Using Deep Learning. Journal of Intelligent & Fuzzy Systems, 39(3), 4785-4801.
6. Marchetti, M., Pierazzi, F., Colajanni, M., & Guido, A. (2016). Analysis of high volumes of network traffic for advanced persistent threat detection. Computer Networks, 109, 127-141.
7. Wang, G., Cui, Y., Wang, J., Wu, L., & Hu, G. (2021). A Novel Method for Detecting Advanced Persistent Threat Attack Based on Belief Rule Base. Applied Sciences, 11(21).
8. Ussath, M., Jaeger, D., Cheng, F., & Meinel, C. (2016). Advanced persistent threats: Behind the scenes. In Information Science and Systems (CISS), 2016 50th Annual Conference on (pp. 181-186). IEEE.
9. Chen, P., Desmet, L., & Huygens, C. (2014). A study on advanced persistent threats. In IFIP International Conference on Communications and Multimedia Security (pp. 63-72). Springer.
10. Sood, A. K., & Enbody, R. J. (2013). Targeted cyber-attacks: a superset of advanced Persistent threats. IEEE security & privacy, 11(1), 54-61.
11. Mell, P., Scarfone, K., & Romanosky, S. (2006). Common vulnerability scoring system. IEEE Security & Privacy, 4(6).
12. Lee, M., & Lewis, D. (2013). Clustering disparate attacks: mapping the activities of the advanced persistent threat.
13. Ullah, F., Edwards, M., Ramdhany, R., Chitchyan, R., Babar, M. A., & Rashid, A. (2018). Data exfiltration: A review of external attack vectors and countermeasures. Journal of Network and Computer Applications.
14. Wang, X., Zheng, K., Niu, X., Wu, B., & Wu, C. (2016). Detection of command and control in advanced persistent threat based on independent access. In Communications (ICC), 2016 IEEE International Conference on. IEEE, pp. 1–6.
15. Yang, L. X., Li, P., Yang, X., & Tang, Y. Y. (2017). Security evaluation of the cyber networks under advanced persistent threats. IEEE Access.
16. Yin, H., Song, D., Egele, M., Kruegel, C., & Kirda, E. (2007). Panorama: capturing system-wide information flow for malware detection and analysis. In Proceedings of the 14th ACM conference on Computer and communications security. ACM, pp. 116–127.
17. Virvilis, N., & Gritzalis, D. (2013). The big four-what we did wrong in advanced persistent threat detection? In Availability, Reliability and Security (ARES), 2013 Eighth International Conference on. IEEE, pp. 248–254.
18. Xu, Z., Ray, S., Subramanyan, P., & Malik, S. (2017). Malware detection using machine learning based analysis of virtual memory access patterns. In 2017 Design, Automation & Test in Europe Conference & Exhibition (DATE). IEEE, pp. 169–174.
19. Vaas, C., & Happa, J. (2017). Detecting disguised processes using application behavior profiling. In Technologies for Homeland Security (HST), 2017 IEEE International Symposium on. IEEE, pp. 1–6.
20. Bohara, A., Thakore, U., & Sanders, W. H. (2016). Intrusion detection in enterprise systems by combining and clustering diverse monitor data. In Proceedings of the Symposium and Bootcamp on the Science of Security. ACM, pp. 7–16.
21. Shalaginov, A., Franke, K., & Huang, X. (2016). Malware beaconing detection by mining large-scale DNS logs for targeted attack identification. In 18th International Conference on Computational Intelligence in Security Information Systems. WASET.
22. Lajevardi, A. M., & Amini, M. (2021). Big knowledge-based semantic correlation for detecting slow and low-level advanced persistent threats. Journal of Big Data, 8(1), 48.
23. Shang, L., Guo, D., Ji, Y., & Li, Q. (2021). Discovering unknown advanced persistent threat using shared features mined by neural networks. Computer Networks, 189, 108121.
24. Hernandez Guillen, J. D., Martin del Rey, A., & Casado-Vara, R. (2021). Propagation of the Malware Used in APTs Based on Dynamic Bayesian Networks. Mathematics, 9(3), 335.
25. Wei, C., Li, Q., Guo, D., & Meng, X. (2021). Toward Identifying APT Malware through API System Calls. Security and Communication Networks, 2021, 6654081.
26. GiuseppeLaurenza/I_F_Identifier dataset,取自https://github.com/GiuseppeLaurenza/I_F_Identifier,于2022年9月访问。
