scikit-learn简介
scikit-learn是一个支持有监督和无监督学习的开源机器学习库
用户指南:https://scikit-learn.org/stable/user_guide.html#user-guide
分类:识别对象属于哪个类别;应用:垃圾邮件检测,图像识别;算法:SVM、最近邻,随机森林

回归:预测与对象关联的连续值属性;应用:药物反应,股票价格;算法:SVR,最近邻,随机森林

聚类:自动将相似对象分组到集合中;应用:客户细分,分组实验;算法:K-Means,谱聚类,均值偏移

降维:减少要考虑的随机变量的数量;应用:可视化,提高效率;算法:K-Means,特征选择,非负矩阵分解

型号选择:比较,验证和选择参数和模型;应用:通过参数提高准确性;算法:网络搜索,交叉验证,指标

预处理:特征提取和归一化;应用:转换输入数据用于机器学习算法;算法:预处理,特征提取

分类与聚类的区别
分类(监督学习):根据文本的特征或属性,划分到已有的类别中。这些类别是已知的。通过对已知分类的数据进行训练和学习,找到这些不同类的特征,再对未分类的数据进行分类
聚类(无监督学习):根本不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。
监督学习
决策树
决策树 (DTs)是一种用于分类和回归的非参数监督学习方法。目标是创建一个模型,通过学习从数据特征推断出的简单决策规则来预测目标变量的值。
分类
DecisionTreeClassifier 是能够对数据集执行多类分类的类。将两个数组作为输入:保存训练样本的形状为稀疏或密集的数组 X,以及保存训练样本的类标签的整数值数组 Y
>>> from sklearn import tree >>> X = [[0, 0], [1, 1]] >>> Y = [0, 1] >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, Y)
拟合后,该模型可用于预测样本类别:
>>> clf.predict([[2., 2.]]) array([1])
如果有多个类具有相同且最高的概率,分类器将预测这些类中具有最低索引的类。
作为输出特定类的替代方法,可以预测每个类的概率,即叶子中该类的训练样本的分数:
>>> clf.predict_proba([[2., 2.]]) array([[0., 1.]])
能够进行二元(标签为 [-1, 1])分类和多类(标签为 [0, …, K-1])分类。
使用 Iris 数据集,我们可以构建一棵树,如下所示:
>>> from sklearn.datasets import load_iris >>> from sklearn import tree >>> iris = load_iris() >>> X, y = iris.data, iris.target >>> clf = tree.DecisionTreeClassifier() >>> clf = clf.fit(X, y)
训练完成后,您可以使用以下plot_tree函数绘制树:

利用graphviz导出树
>>> import graphviz >>> dot_data = tree.export_graphviz(clf, out_file=None) >>> graph = graphviz.Source(dot_data) >>> graph.render("iris")
export_graphviz也支持多种美化选项,包括可以通过类着色节点(或值回归)和显式的变量和类名称。Jupyter notebooks也会自动内联渲染这些图。
>>> dot_data = tree.export_graphviz(clf, out_file=None, ... feature_names=iris.feature_names, ... class_names=iris.target_names, ... filled=True, rounded=True, ... special_characters=True) >>> graph = graphviz.Source(dot_data) >>> graph
或者,也可以使用函数以文本格式导出树export_text。这种方法不需要安装外部库,更紧凑:
>>> from sklearn.datasets import load_iris >>> from sklearn.tree import DecisionTreeClassifier >>> from sklearn.tree import export_text >>> iris = load_iris() >>> decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2) >>> decision_tree = decision_tree.fit(iris.data, iris.target) >>> r = export_text(decision_tree, feature_names=iris['feature_names']) >>> print(r) |--- petal width (cm) <= 0.80 | |--- class: 0 |--- petal width (cm) > 0.80 | |--- petal width (cm) <= 1.75 | | |--- class: 1 | |--- petal width (cm) > 1.75 | | |--- class: 2
回归
使用DecisionTreeRegressor类,决策树也可以应用于回归问题 。
fit 方法将作为参数数组 X 和 y,只是在这种情况下,y 应该具有浮点值而不是整数值:
>>> from sklearn import tree >>> X = [[0, 0], [2, 2]] >>> y = [0.5, 2.5] >>> clf = tree.DecisionTreeRegressor() >>> clf = clf.fit(X, y) >>> clf.predict([[1, 1]]) array([0.5])
无监督学习
聚类
可以使用sklearn.cluster模块对未标记的数据进行聚类
每个聚类算法都有两种变体:
一个类:它实现了fit在训练数据上学习聚类的方法,可以在labels_上找到训练数据上的标签
一个函数:给定训练数据,返回一个与不同聚类相对应的整数标签数组。
聚类方法概述
K-Means算法
参考链接:https://www.cnblogs.com/pinard/p/6169370.html
参考链接:https://scikit-learn.org/stable/modules/clustering.html
在scikit-learn中,包括两个K-Means的算法,一个是传统的K-Means算法,对应的类是KMeans。另一个是基于采样的Mini Batch K-Means算法,对应的类是MiniBatchKMeans
K-Means算法通过尝试将样本分成n个方差相等的组来对数据进行聚类,最小化称为惯性或聚类内平方和的标准。该算法需要指定簇的数量。
算法步骤:
1. 选择初始质心:最基本的方法是选择k数据集中的样本X。
初始化后,K-means由2、3步骤之间的循环组成。
2. 将每个样本分配到其最近的质心
3. 通过取分配给每个先前质心的所有样本的平均值来创建新的质心
4. 计算旧质心和新质心之间的差异,算法重复2、3两个步骤,直到该值小于阈值(重复直到质心没有明显移动)
K-means 等效于期望最大化算法,它具有一个小的、全等的对角协方差矩阵. 如果有足够的时间,K-means 将始终收敛,但这可能会达到局部最小值。
K-means高度依赖于质心的初始化,质心不同会影响计算次数,解决这一问题的方法是k-means++初始化方案,该方案已经在scikit-learn中实现(使用init=’k-means++’参数),这会将质心初始化为彼此远离,从而可能比随机初始化产生更好的效果。
K-means++ 也可以独立调用,为其他聚类算法选择种子,详见sklearn.cluster.kmeans_plusplus详情和示例用法。
该算法支持样本权重,可以通过参数给出 sample_weight。这允许在计算聚类中心和惯性值时为某些样本分配更多权重。
低级并行
可以并行处理小块数据(256个样本),此外还可以减少内存占用。
MiniBatchKMeans
是KMeans算法的一种变体,使用小批量来减少计算时间。同时仍试图优化相同的目标函数。小批量是输入数据的子集,在每次训练迭代中随机采样。这些小批量大大减少了收敛到本地解决方案所需的计算量。与其他减少 k-means 收敛时间的算法相比,mini-batch k-means 产生的结果通常比标准算法稍差。
该算法在两个主要步骤之间迭代,类似于 vanilla k-means。
1. 从数据集中随机抽取样本b,形成一个小批量。然后将他们分配给最近的质心。
2. 更新质心。与K-means相比,这是在每个样本的基础上完成的。
通过获取样本的流平均和分配给该质心的所有先前样本来更新分配的质心,具有降低质心随时间变化率的效果。执行这些步骤直到收敛或达到预定的迭代次数。
MiniBatchKMeans收敛速度比 快KMeans,但结果的质量会降低。在实践中,这种质量差异可能非常小。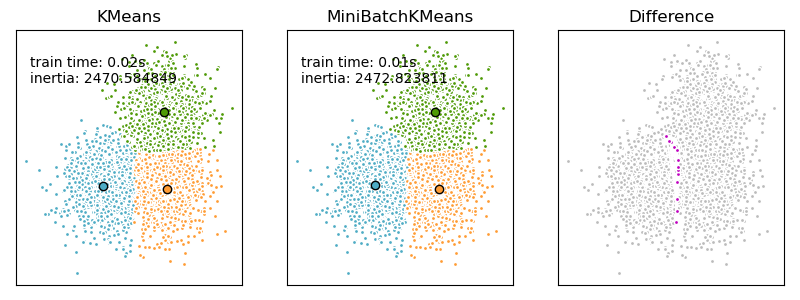
K值评估
监督聚类没有样本输出,也就没有比较直接的聚类评估方法。但是我们可以从簇内的稠密程度和簇间的离散程度来评估聚类的效果。常见的方法有轮廓系数Silhouette Coefficient和Calinski-Harabasz Index。
Calinski-Harabasz Index计算简单直接,得到的Calinski-Harabasz分数值ss越大则聚类效果越好:
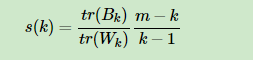
其中m为训练集样本数,k为类别数。BkBk为类别之间的协方差矩阵,WkWk为类别内部数据的协方差矩阵。trtr为矩阵的迹。也就是说,类别内部数据的协方差越小越好,类别之间的协方差越大越好,这样的Calinski-Harabasz分数会高。在scikit-learn中, Calinski-Harabasz Index对应的方法是metrics.calinski_harabaz_score.
模块调用
sklearn.cluster模块收集了流行的无监督聚类算法。
| Class | 名称 |
| cluster.KMeans([n_clusters, init, n_init, …]) | K-Means 聚类 |
| cluster.MiniBatchKMeans([n_clusters, init, …]) | Mini-Batch K-Means 聚类 |
Kmeans参数详解:
1) n_clusters: 即我们的k值,一般需要多试一些值以获得较好的聚类效果。
2)max_iter: 最大的迭代次数,一般如果是凸数据集的话可以不管这个值,如果数据集不是凸的,可能很难收敛,此时可以指定最大的迭代次数让算法可以及时退出循环。
3)n_init:用不同的初始化质心运行算法的次数。由于K-Means是结果受初始值影响的局部最优的迭代算法,因此需要多跑几次以选择一个较好的聚类效果,默认是10,一般不需要改。如果你的k值较大,则可以适当增大这个值。
4)init: 即初始值选择的方式,可以为完全随机选择’random’,优化过的’k-means++’或者自己指定初始化的k个质心。一般建议使用默认的’k-means++’。
5)algorithm:有“auto”, “full” or “elkan”三种选择。”full”就是我们传统的K-Means算法, “elkan”是我们原理篇讲的elkan K-Means算法。默认的”auto”则会根据数据值是否是稀疏的,来决定如何选择”full”和“elkan”。一般数据是稠密的,那么就是 “elkan”,否则就是”full”。一般来说建议直接用默认的”auto”
MiniBatchKMeans参数详解
1) n_clusters: 即我们的k值,和KMeans类的n_clusters意义一样。
2)max_iter:最大的迭代次数, 和KMeans类的max_iter意义一样。
3)n_init:用不同的初始化质心运行算法的次数。这里和KMeans类意义稍有不同,KMeans类里的n_init是用同样的训练集数据来跑不同的初始化质心从而运行算法。而MiniBatchKMeans类的n_init则是每次用不一样的采样数据集来跑不同的初始化质心运行算法。
4)batch_size:即用来跑Mini Batch KMeans算法的采样集的大小,默认是100.如果发现数据集的类别较多或者噪音点较多,需要增加这个值以达到较好的聚类效果。
5)init: 即初始值选择的方式,和KMeans类的init意义一样。
6)init_size: 用来做质心初始值候选的样本个数,默认是batch_size的3倍,一般用默认值就可以了。
7)reassignment_ratio: 某个类别质心被重新赋值的最大次数比例,这个和max_iter一样是为了控制算法运行时间的。这个比例是占样本总数的比例,乘以样本总数就得到了每个类别质心可以重新赋值的次数。如果取值较高的话算法收敛时间可能会增加,尤其是那些暂时拥有样本数较少的质心。默认是0.01。如果数据量不是超大的话,比如1w以下,建议使用默认值。如果数据量超过1w,类别又比较多,可能需要适当减少这个比例值。具体要根据训练集来决定。
8)max_no_improvement:即连续多少个Mini Batch没有改善聚类效果的话,就停止算法, 和reassignment_ratio, max_iter一样是为了控制算法运行时间的。默认是10.一般用默认值就足够了。
函数调用
| 函数 | 名称 |
| cluster.k_means(X, n_clusters, *[, …]) | 执行K-Means 聚类算法 |
| cluster.kmeans_plusplus(X, n_clusters, *[, …]) | 根据 k-means++ 初始化 n_clusters 种子 |
